62 KiB
DevOps & CI/CD
DevOps und CI/CD sind verwandte Themengebiete mit starken Überschneidungen.
Definition: DevOps
DevOps, eine Kombination aus Development und Operations, bezeichnet die enge Zusammenarbeit zwischen Entwicklern und IT-Operatoren. Das Ziel ist es, den Produktlebenszyklus durch frühzeitige Berücksichtigung von Betriebsanforderungen zu beschleunigen. Die Zusammenarbeit umfasst folgende Aspekte:
- Implementierung der Automatisierung von Entwicklungs-, Test- und Deployment-Prozessen, um manuelle Fehler zu reduzieren und Effizienz zu steigern.
- Umsetzung von kontinuierlicher Integration (CI) und kontinuierlicher Bereitstellung (CD) für schnelle und zuverlässige Softwareauslieferung.
- Kurze Feedback-Schleifen, um schnell auf Änderungen reagieren und Probleme zeitnah beheben zu können.
- Förderung einer Kultur der Zusammenarbeit und des Lernens zur Unterstützung des Wissensaustauschs und kontinuierlicher Prozessverbesserungen.
Typische DevOps-Tools sind:
- Docker: Eine Plattform zur Erstellung, zum Versand und Betrieb von Anwendungen in isolierten Umgebungen (Containern).
- Docker-Compose: Ein Tool für Docker, das Multi-Container Docker-Anwendungen vereinfacht und als Code definiert.
- Ansible: Ein Open-Source-Automatisierungstool für Konfigurationsmanagement, Anwendungsdeployment und vieles mehr.
- Kubernetes: Ein Open-Source-System zur Orchestrierung von containerisierten Anwendungen.
- Terraform: Ein Infrastruktur-als-Code-Tool zum sicheren und effizienten Aufbau, Ändern und Versionieren von Infrastruktur.
- Configuration as Code: Ein Ansatz, bei dem Konfigurationen ähnlich wie Code in Versionskontrollsystemen gespeichert und versioniert werden.
Der typische DevOps-Arbeitsfluss wird im folgenden Diagramm dargestellt:
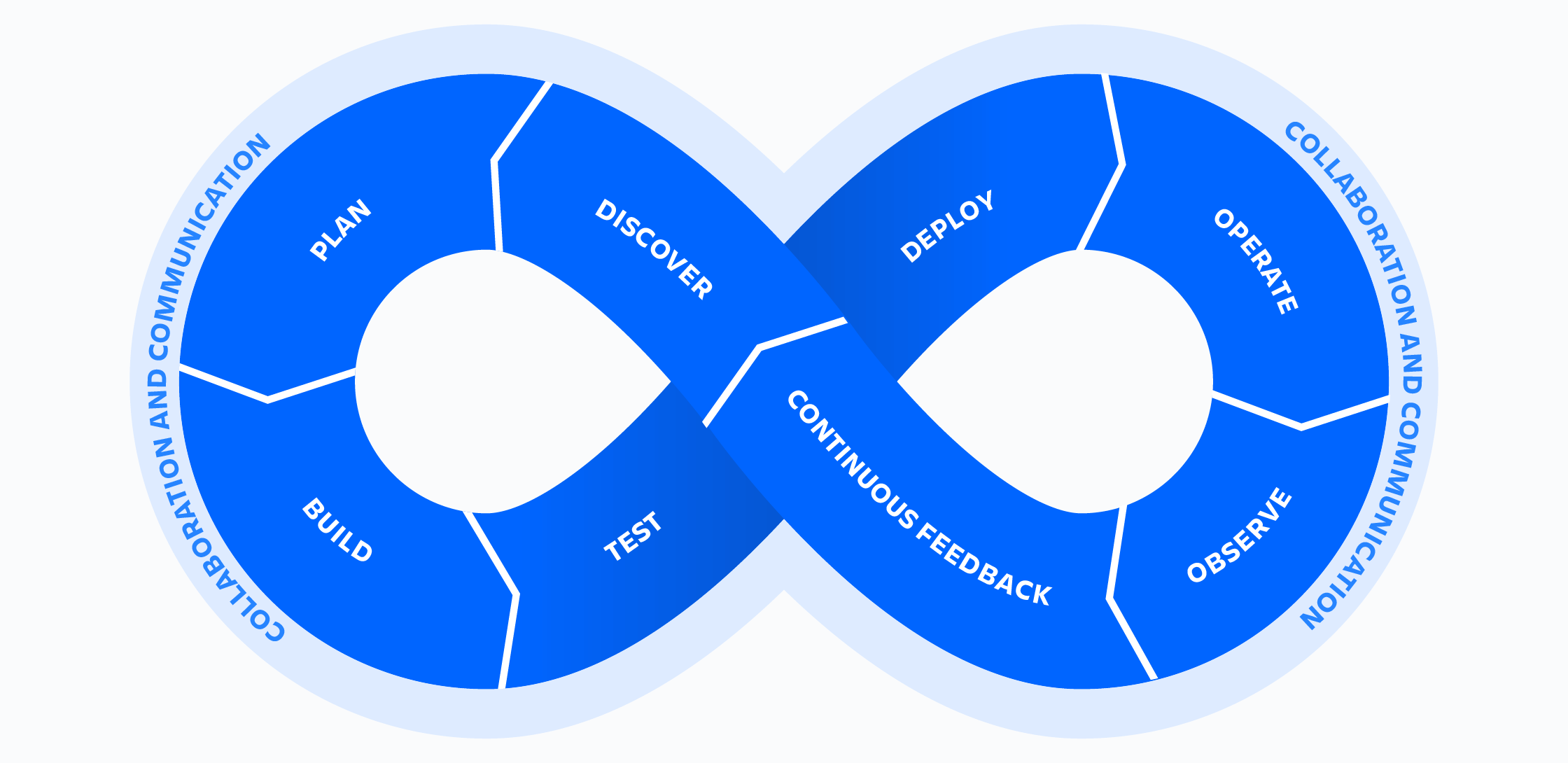 Quelle: Atlassian
Quelle: Atlassian
Definition CI/CD
CI/CD steht für kontinuierliche Integration (Continuous Integration) und kontinuierliches Deployment (Continuous Deployment). Dieser Ansatz in der Softwareentwicklung fokussiert auf die Entwicklung kleiner, in sich geschlossener Softwareteile. Diese werden schnell in einen oder mehrere Hauptstränge integriert, meist über eine geeignete Git Branching-Strategie. In unserem Projekt, das sich auf Entwicklung konzentriert, erfolgt die Integration ausschließlich in den Main Branch.
Jede Integration in den Main Branch wird möglichst vollständig automatisch getestet, bevor sie freigegeben wird. Tests können unterschiedlich gestaltet sein, von Unit-Tests bis zu statischen Codeanalysen. Das bekannteste Framework für Unit-Tests in Python ist pytest. Zusätzlich werden oft statische Codeanalysen wie ruff oder mypy eingesetzt.
Der Code wird oft vor der Integration einem verpflichtenden Review unterzogen. Review-Vorgaben lassen sich in Werkzeugen wie GitHub, GitLab und Gitea konfigurieren.
Dieses Vorgehen ermöglicht eine kleinschrittige, stetige Verbesserung und eine relativ einfache sowie kostengünstige Integration von Veränderungen in die Codebasis. Durch den geringen Umfang der Veränderungen und das automatische Testen können Fehler vermieden oder frühzeitig gefunden und einfach repariert werden.
Dependency Management in Python
Für das Dependency Management in Python gibt es verschiedene Werkzeuge. Je nach Anwendungsfall und Erstellungszeitpunkt eines Projekts kommen unterschiedliche Tools zum Einsatz. Hier einige Beispiele:
requirements.txt
Eine requirements.txt ist eine Textdatei, die die Abhängigkeiten eines Projekts auflistet.
Diese können dann komplett mit dem Befehl pip install -r requirements.txt installiert werden.
Das Erstellen und Warten der Datei kann jedoch problematisch sein.
Die requirements.txt listet Abhängigkeiten zeilenweise mit Versionsspezifikationen auf.
Dabei ist es üblich, sowohl direkte als auch indirekte Abhängigkeiten zu listen.
Die Datei wird entweder manuell erstellt oder schreibt die aktuell installierte Abhängigkeitssammlung nieder.
Die aktuell installierten packages werden dabei mit pip freeze > requirements.txt aufgezeichnet.
Dabei gibt es aber keinerlei garantien das die so aufgezeichneten Abhängigkeiten auch zueinander passen.
Indirekte Abhängigkeiten sind die Abhängigkeiten von Abhängigkeiten.
Trotz ihrer Einfachheit wird die requirements.txt oft als Export- oder Zwischenprodukt genutzt.
Eine beispielhafte requirements.txt für die beliebte Bibliothek pandas könnte wie folgt aussehen:
meson-python==0.13.1
meson==1.2.1
wheel
Cython==3.0.5 # Note: sync with setup.py, environment.yml and asv.conf.json
numpy>1.22.4,<=2.0.0.dev0
versioneer[toml]
Es ist wichtig zu wissen, dass eine requirements.txt noch komplexer ausfallen kann, beispielsweise mit Hashwerten der
Abhängigkeiten und Bedingungen für deren Gültigkeit sowie Verweisen auf zusätzliche Paketquellen.
Diese Faktoren erschweren die Wartung der requirements.txt.
Der Name requirements.txt ist dabei eine starke Konvention, aber nicht verpflichtend.
pip-tools
pip-tools ist ein Python-Paket, das das manuelle Erstellen und Pflegen von Abhängigkeiten vereinfacht.
Es nutzt eine requirements.in, in der nur die direkten Abhängigkeiten aufgeführt werden.
Mit dem Befehl pip-compile kann aus der requirements.in eine aktuelle requirements.txt generiert werden, die alle Abhängigkeiten erfüllt.
Diese ist einfacher zu warten als eine rohe requirements.txt.
pip-tools bietet zudem einen Befehl, der installierte Pakete mit einer requirements.txt synchronisiert.
Dies ermöglicht ein einfacheres Arbeiten mit Paketen als mit pip allein.
Der Vorteil zeigt sich besonders in Teamumgebungen oder bei der Entwicklung auf mehreren Geräten.
Da requirements.in und requirements.txt nur starke Konventionen sind, können zusätzlich zu den Anwendungsabhängigkeiten
auch Entwicklungsabhängigkeiten gepflegt werden.
Indirekte Abhängigkeiten können bei mehreren direkten Abhängigkeiten anders ausfallen, was zu unerwartetem Verhalten der Software führen kann.
Ein Lösungsansatz hierfür ist die Erweiterung von pip-tools namens pip-tools-multi.
Üblicherweise werden die requirements.txt Dateien mit den gelösten Abhängigkeiten im Git verwaltet.
pip-compile-multi
pip-tools-multi ermöglicht es, Lösungen für mehrere Gruppen direkter Abhängigkeiten zu definieren.
So kann eine base.in die direkten Laufzeitabhängigkeiten einer Software auflisten.
Inhalte anderer *.in-Dateien können vererbt werden.
Ein Bündel von *.in-Dateien erhält eine Gesamtlösung, aus der diverse *.txt-Dateien im requirements.txt-Stil automatisch generiert werden.
Damit lassen sich zusätzliche Pakete für Testen, Linten und Entwickeln pflegen, ohne die Laufzeitumgebungspakete zu beeinflussen.
Die generierten *.txt-Dateien mit den gelösten Abhängigkeiten werden üblicherweise im Git verwaltet.
poetry
Das neueste Werkzeug zur Verwaltung von Python-Abhängigkeiten ist poetry.
Aktuell ist Poetry "Stand der Technik" und wird in vielen aktiv entwickelten Projekten genutzt.
pyproject.toml
Anders als die bisher vorgestellten Lösungen nutzt poetry die pyproject.toml zur Verwaltung von Abhängigkeiten.
Die pyproject.toml wurde in PEP 518 vorgestellt und in den PEPs 517,
621 und 660 weiter ausgeführt.
Ziel der pyproject.toml ist es, eine einzelne Datei zu definieren, in der alle Konfigurationen eines Python-Projekts enthalten sind,
einschließlich Build- und Abhängigkeitssystem.
Abhängigkeitsverwaltung mit poetry
Der Befehl poetry new project-name erstellt eine Poetry-Projektstruktur.
Diese umfasst pyproject.toml, README.md, ein Paket und einen Testordner.
Mit poetry init lässt sich ein bestehendes Projekt um eine poetry-Sektion erweitern.
Dadurch entsteht in der pyproject.toml eine grundlegende Konfiguration.
Für Ergänzungen und detaillierte Optionen verweise ich auf die umfangreiche Dokumentation unter python-poetry.org.
Die pyproject.toml enthält nun Sektionen, die Laufzeit-, Test- und Entwicklungsabhängigkeiten in frei definierbaren Gruppen deklarieren.
Ein Beispiel hierfür könnte wie folgt aussehen:
[tool.poetry]
authors = ["AKI Projektgruppe 23"]
classifiers = []
description = "Some describing Text!"
documentation = "https://some-url.eu/"
homepage = "https://some-url.eu/"
keywords = ["deutschland", "economy", "transparenzregister", "dataintegration", "handelsregister"]
maintainers = []
name = "aki-prj23-transparenzregister"
packages = [{include = "aki_prj23_transparenzregister", from = "src"}]
readme = "README.md"
repository = "https://github.com/fhswf/aki_prj23_transparenzregister"
version = "0.1.0"
[tool.poetry.dependencies]
pandas = "^2.0.0"
[tool.poetry.group.develop.dependencies]
black = {extras = ["jupyter"], version = "*"}
jupyterlab = "*"
pre-commit = "*"
[tool.poetry.group.lint.dependencies]
black = "*"
mypy = "*"
pandas-stubs = "*"
pip-audit = "*"
pip-licenses = "*"
ruff = "*"
[tool.poetry.group.test.dependencies]
pytest = "^7.4.2"
Mit den Befehlen poetry update oder poetry lock wird aus der pyproject.toml eine poetry.lock-Datei generiert.
Diese Datei erfüllt eine ähnliche Funktion wie die requirements.txt, zeichnet aber zusätzlich den Abhängigkeitsbaum auf welcher in der poetry.lock mit aufgezeichnet wird.
So bietet sie eine übersichtliche Verwaltung der direkten und indirekten Abhängigkeiten.
Poetry cheat sheet
-
poetry install(--with,--without,--only)
Funktionalität: Installiert die Abhängigkeiten, die in der pyproject.toml Datei aufgelistet sind.--with: Ermöglicht das explizite Hinzufügen von optionalen Gruppen von Abhängigkeiten zur Installation.--without: Schließt bestimmte Gruppen von Abhängigkeiten von der Installation aus.--only: Installiert ausschließlich die angegebenen Abhängigkeitsgruppen und ignoriert alle anderen.
-
poetry update
Funktionalität: Aktualisiert die Abhängigkeiten eines Projekts auf ihre neuesten verfügbaren Versionen, basierend auf den Einschränkungen, die in der pyproject.toml-Datei definiert sind. Details:- Bei der Ausführung überprüft poetry update, ob es neuere Versionen der in pyproject.toml definierten Paketabhängigkeiten gibt, die mit den spezifizierten Versionseinschränkungen kompatibel sind.
- Es aktualisiert die
poetry.lock-Datei, um diese neuen Versionen widerzuspiegeln, wodurch sichergestellt wird, dass bei zukünftigen Installationen mit poetry install genau diese Versionen verwendet werden. - Man kann spezifische Pakete für die Aktualisierung auswählen, indem man sie als Argumente hinzufügt (z.B. poetry update flask aktualisiert nur Flask und seine Abhängigkeiten). Keine zusätzlichen Optionen: Der Befehl hat keine weiteren Modifikatoren oder Optionen.
- Je nachdem wie die Version festgelegt wurde, werden Updates auf patches (
~1.2.3=>>=1.2.3 < 1.3.0), oder minor (^1.2.3=>>=1.2.3 <2.0.0) Versions begrenzt .
-
poetry add(--group)
Funktionalität: Fügt eine neue Abhängigkeit zum Projekt hinzu.- Option --group: Mit dieser Option kann die Abhängigkeit einer spezifischen Gruppe zugeordnet werden, z.B. development oder testing. Dies ist nützlich, um Abhängigkeiten, die nur in bestimmten Umgebungen benötigt werden, separat zu verwalten.
- Versionsrestriktionen können mit einem
@an die Abhängigkeit angefügt werden. Diese sind Standardmäßig die aktuelle Version bis zur nächsten Hauptversion in der Zirkumflex-Schreibweise (^1.2.3).
-
poetry remove
Funktionalität: Entfernt eine bestehende Abhängigkeit aus dem Projekt. -
poetry build
Funktionalität: Erstellt das Paket für das Projekt. Dies umfasst typischerweise die Erstellung von wheel- und sdist-Archiven. Keine zusätzlichen Optionen: Dieser Befehl kompiliert das Projekt in ein Format, das auf PyPI oder anderen Paket-Indizes veröffentlicht werden kann. -
poetry publish
Funktionalität: Veröffentlicht das Paket auf einem Paket-Index wie PyPI. Wichtige Optionen:--repository: Gibt das Repository an, auf das das Paket hochgeladen werden soll.--username,--password: Für die Authentifizierung bei einem privaten Repository.--build: Führt automatisch poetry build vor dem Veröffentlichen aus.
-
poetry lock
Funktionalität: Locked die dependencies wiepoetry updateaber ohne diese Direkt zu installieren.
Cython
Poetry unterstützt das Bauen von Cython-Modulen, obwohl diese Unterstützung nur inoffiziell ist und keine offizielle Dokumentation existiert. In unserem Projekt ist der Einsatz von Cython jedoch nicht vorgesehen.
Extras
poetry bietet die Möglichkeit, Extras zu definieren.
Extras sind Abhängigkeitsgruppen, die bei Bedarf installiert werden.
Dabei wird die Gesamtlösung der Abhängigkeiten über alle Gruppen hinweg erstellt.
Die direkten und indirekten Abhängigkeiten werden nur installiert, wenn eine spezifische Extragruppe bei der Installation eines Python Wheels angefordert wird.
Bei der untenstehenden Konfiguration würde pip install <some-package> lediglich pandas als Abhängigkeit installieren.
Der Befehl pip install <some-package>[ai] würde zusätzlich tensorflow und alle dessen indirekten Abhängigkeiten installieren.
[tool.poetry.dependencies]
pandas = "^2.0.0"
tensorflow = "^2.10.0"
[tool.poetry.extras]
ai = ["tensorflow"]
Natürlich können mehrere Extragruppen konfiguriert werden.
Script Entry Points
In der pyproject.toml können Einstiegspunkte für das Skript definiert werden.
Diese werden bei der nächsten Ausführung von poetry install erstellt.
Auch ein kompiliertes Python-Wheel erstellt diese Einstiegspunkte während der Installation.
Die Definitionen für Einstiegspunkte können wie folgt aussehen:
[tool.poetry.scripts]
start-program = "package.module:method"
Mehrere Einstiegspunkte können in der Konfiguration definiert werden.
Nach der Installation über poetry install oder die Installation eines fertigen wheels steht der start-program-Einstiegspunkt zur Verfügung.
Dieser führt die Methode method aus dem Paket package und dem Modul module aus.
Ist das Python-script-Verzeichnis im PATH gelistet, steht das Kommando auch global zur Verfügung.
Linter
Der Begriff Lint leitet sich vom englischen Wort für "Fussel" ab und bezeichnet die statische Codeanalyse.
Hierbei wird der Programmcode auf Schwachstellen, Fehler, Sicherheitslücken oder Verstöße gegen Codekonventionen analysiert, ohne ihn auszuführen.
In Python, einer nicht kompilierten und schwach typisierten Sprache, werden viele Fehler erst bei der Ausführung sichtbar. In Compilierten und streng typisierten Programmiersprachen werden viele Probleme schon in der Compilezeit sichtbar. Einige Fehler treten nur unter seltenen Umständen auf. Daher ist die strukturelle Analyse des Codes in Python besonders wichtig.
Es gibt verschiedene Programme für Python, die unterschiedliche Analysen durchführen. Im Folgenden werden die aktuell wichtigsten Werkzeuge vorgestellt.
mypy
mypy ist ein von der Python Foundation gewartetes Werkzeug, das die Typisierung in Python statisch überprüft.
Obwohl Python eine schwach typisierte Programmiersprache ist, überwiegen in größeren Projekten oft die Nachteile dieser Eigenschaft.
Die Einführung einer Typisierung wird dann sinnvoller, insbesondere wenn Teammitglieder mit Funktionen und Klassen arbeiten, die von anderen entwickelt wurden.
Das Fehlerpotenzial durch unzulässige oder ungetestete Zuweisungen kann durch optionale Typisierung in Python verringert werden, besonders effektiv in Kombination mit einem Linter wie mypy.
mypy führt eine statische Code-Analyse durch und identifiziert widersprüchliche Zuweisungen sowie unzulässige Argumente, wobei Lösungshinweise oder Fehlerbeschreibungen bereitgestellt werden.
Typisierung in Python
In Mypy erhalten Variablenzuweisungen, wenn bestimmbar, den Typ der ersten Zuweisung. Der Stil der Typisierung hat sich in fast jeder der letzten Python-Versionen geändert, daher wird hier nur auf die Typisierung wie in Python 3.11 implementiert eingegangen. Die folgenden beiden Zuweisungen sind sowohl in der Zuweisung als auch im Typ für Mypy identisch:
Variablenzuweisung:
u_number = 5
t_number: int = 5
Ein Funktionskopf kann beispielhaft wie folgt typisiert werden:
Funktionskopf:
def some_funtion_name(
arg1: int,
arg2: list[int | SomeClass | None] = None
) -> OtherClass:
# ...
# do something
# ...
return OtherClass()
Typisierung bietet neben der Dokumentation weitere Vorteile.
Sie unterstützt die Autovervollständigung in IDEs wie PyCharm, Visual Studio Code oder Jupyter.
Zudem enthalten Typisierungen Informationen, die von Language Models (LLMs) genutzt werden können.
Diese Modelle bearbeiten, vervollständigen, dokumentieren oder erklären Code unter Berücksichtigung der Typisierung.
Vor allem aber gibt die Typisierung werkzeugen wie mypy anhaltspunkte darüber welche Typen für einen Wert bzw. Rückgabewert erwartet werden.
Dies kann dan über statische Analysen abgeglichen werden.
mypy ist nicht immer in der Lage, Typen korrekt zu inferieren.
Dies kann an unvollständigem Code liegen.
Ist der Code jedoch korrekt, kann der Kommentar # type: ignore verwendet werden, um die Typüberprüfung für einzelne Zeilen zu unterdrücken.
Die Unterdrückung der Typisierungsprüfung sollte nur erfolgen, wenn man sich sicher ist, dass dies notwendig ist.
ruff
ruff ist eine Neuentwicklung in Rust, basierend auf verschiedenen anderen Werkzeugen.
Es folgt eine unvollständige Liste wichtiger Linter, die in ruff reimplementiert wurden:
flake8: Dieses Werkzeug überprüft Quellcode auf die Einhaltung des PEP 8-Stils, Programmierfehler und Komplexität. Es kombiniert verschiedene Tools wie PyFlakes, pycodestyle und McCabe.isort: Sortiert Importe in Python-Dateien. Isort automatisiert die Sortierung und Trennung von Importen in Abschnitte sowie deren alphabetische Anordnung zur Verbesserung der Lesbarkeit.pylint: Ein umfassendes Werkzeug, das nach Programmierfehlern sucht, den Code-Stil zu standardisieren versucht und die Refaktorisierung von Code vorschlägt. Pylint bietet detaillierte Berichte über potenzielle Codeprobleme.bandit: Speziell für die Sicherheitsprüfung von Python-Code entwickelt. Es durchsucht den Code nach häufigen Sicherheitslücken und warnt bei potenziell unsicheren Konstrukten.flake8-Plugins:ruffimplementiert auch einige gängige flake8-Plugins. Diese Plugins erweitern flake8 um zusätzliche Prüfungen und Funktionen, die über die Standardfunktionen hinausgehen.
Im Gegensatz zu flake8, bandit und pylint kann ruff einfache Korrekturen selbstständig durchführen.
Dies führt dazu, dass Nutzern manche Regeln möglicherweise nicht bewusst werden, aber sie werden nicht von unwichtigen Problemen aufgehalten.
ruff wird in der pyproject.toml konfiguriert, wo einzelne Regelsätze und individuelle Regeln aktiviert oder deaktiviert werden können.
Die Beschleunigung gegenüber bekannten Lintern beträgt etwa 1000%, was auch das Problem der Pluginhölle und der Mehrfachausführung verschiedener Tools beseitigt.
Wichtig zu wissen ist, dass ruff Dateien isoliert analysiert, im Gegensatz zu anderen Programmen.
Dies führt manchmal zu Fehlern, wie dem Nichterkennen vererbter Docstrings über Dateigrenzen hinweg, was zu fehlerhaften Erkennungen führen kann.
Tools wie ruff sind besonders nützlich für Python-Einsteiger, da sie viele stilistische Details im Code verfeinern und Verbesserungspotentiale hervorheben.
So werden Styleguides wie PEP-8 nach und nach erschlossen, ohne Nutzer mit umfangreichen Informationen zu überfordern.
ruff Fehlercodes können durch den # noqa Kommentar lokal unterdrückt werden.
Es ist jedoch besser, die Unterdrückung spezifisch mit # noqa: F1, F2 durchzuführen, um z. B. die Fehlercodes F1 und F2 zu unterdrücken.
Die alleinige Verwendung von # noqa unterdrückt alles und ist daher nicht empfohlen.
Die Fehlercodes werden bei der Ausführung von ruff angezeigt.
black
black ist ein Linter, der sich ausschließlich um die menschliche Lesbarkeit des Codes kümmert.
Er formatiert Whitespace nach immer gleichen Mustern.
Dadurch sieht der Code konsistent aus, was mehrere Ziele erfüllt:
- Der Programmierer muss sich nicht um die Formatierung kümmern.
- Andere Programmierer müssen sich nicht an unterschiedliche Formatierungen gewöhnen.
blacklässt sich kaum konfigurieren, sodass alle damit formatierten Projekte gleich aussehen. Die somit erreichte konsistenz reduziert den mentalen Overhead beim Lesen und erhöht somit das Verständnis.
Für einen tieferen Einblick in die Philosophie von black empfiehlt sich der Vortrag des Autors auf der PyCon.
Black hat sich als inoffizieller Standard für die Python-Codeformatierung etabliert.
pip-audit
pip-audit ist ein OWASP-Abhängigkeitsscanner für Python.
Er scannt installierte oder in einer requirements.txt festgelegte Abhängigkeiten auf bekannte Sicherheitslücken.
Es ist redundant, wenn GitHubs Dependabot verwendet wird.
Eine kostenpflichtige Alternative ist das safety-Tool, das schneller Sicherheitslücken aktualisiert und möglichkeiten zur Korrektur durch automatische Updates bietet.
Auch safety ist redundant, wenn Dependabot genutzt wird.
pip-licenses
pip-licenses listet und analysiert die Lizenzen der verwendeten Abhängigkeiten.
Es kann überprüfen, ob nur Software mit erlaubten oder nicht verbotenen Lizenzen verwendet wurde.
Die Liste der erlaubten und verbotenen Lizenzen ist frei konfigurierbar.
Für akademische Projekte ist dies weniger wichtig und daher nicht implementiert, wird aber der Vollständigkeit halber erwähnt.
In einem Corporate/Compliance Kontext ist dies aber natürlich von Bedeutung.
pytest
Um die anfängliche Funktionalität und Stabilität von Programmteilen sicherzustellen, ist es sinnvoll, Tests zu schreiben, auch im Hinblick auf spätere Modifikationen!
Diese vergleichen die Rückgabewerte von Funktionen mit Erwartungswerten.
Python wird mit einem integrierten Test-Framework ausgeliefert, oft wird jedoch pytest aufgrund der einfacher Syntax verwendet.
Hier ein einfaches Beispiel für Code und Test:
def addition(a: int, b: int) -> int:
"""Die Funktion welche zu testen ist."""
return a + b
def test_addition() -> None:
"""Ein Test für die Funktion addition."""
assert addition(1, 5) == 6
Tests werden üblicherweise im tests-Verzeichnis angelegt.
pytest durchsucht dieses Verzeichnis nach Dateien, die auf *_test.py enden, und registriert darin alle Funktionen, die mit test beginnen, als Tests.
Diese Tests werden dann nacheinander ausgeführt.
Nicht alle Tests sind so einfach wie das oben dargestellte Beispiel.
Oft müssen mehrere Schritte ausgeführt werden.
Es ist jedoch ratsam, Funktionen unabhängig und kleinschrittig in einzelnen Tests zu überprüfen.
Das führt zu besserer Übersichtlichkeit, besonders wenn Tests fehlschlagen da so eine Gesamtübersicht über das Fehlerverhalten vorliegt.
Einige Abhängigkeiten bieten eigene assert-Funktionen.
Zum Beispiel enthält pandas Funktionen wie pandas.testing.assert_frame_equal, pandas.testing.assert_series_equal und pandas.testing.assert_index_equal, die pandas-Objekte vergleichen und verschiedene Assertions durchführen.
Meine persönliche Präferenz ist es jedoch, wenn möglich, pandas-Objekte in Dictionaries zu konvertieren und diese dann mit assert zu vergleichen, da dabei fehlschlagende Vergleiche aussagekräftiger sind.
Dies ist jedoch eine persönliche Präferenz.
Auch numpy enthält ein testing-Unterpaket.
Globale Konfigurationen oder Code, der vor dem ersten Test ausgeführt werden soll, können in der conftest.py im tests-Ordner abgelegt werden.
Setup und Teardown
Manche Tests erfordern einen Aufbau (setup) und ein nachfolgendes Aufräumen (teardown).
Dies wird auch als "setup and teardown" bezeichnet.
In pytest erfolgt dies über Fixtures.
Fixtures sind Funktionen, die mit dem pytest.fixture-Decorator versehen werden.
Dieser wandelt eine Funktion in eine Fixture um.
Zusätzlich können Einstellungen vorgenommen werden, wie beispielsweise die Nutzungsdauer und der Geltungsbereich der Fixture.
Beispiele für die Nutzung von Fixtures sind:
- Erstellung und Löschung von Dateisystemen.
- Erstellung von Datenbank-Sessions oder Datenbanken (SQLite).
- Überschreiben von Funktionen und Umgebungsvariablen.
- Mocken von Netzwerkverbindungen/Sessions.
Eine Fixture teilt sich in einen Setup-, einen Teardown-Teil und yield auf.
Im Setup-Teil werden Vorbereitungen für ein Testelement durchgeführt.
Im Teardown-Teil wird dieses Element aufgeräumt, falls notwendig.
yield trennt Setup und Teardown.
yield übergibt ein Objekt oder einen Wert an den Test und pausiert die Ausführung der Fixture, bis die Tests im Scope abgeschlossen sind.
Der Teardown wird nach Abschluss der Tests durchgeführt. Das garantiert, dass auch bei fehlschlagenden oder nicht durchführbaren Tests aufgeräumt wird.
Wird kein Teardown benötigt, wird konventionell return anstelle von yield verwendet.
Fixtures können auf anderen Fixtures aufbauen.
Eine Fixture wird verwendet, indem der Methodenname als Argument einem Test hinzugefügt wird oder autouse=True im Decorator gesetzt wird.
Alternativ kann der pytest.mark.usefixtures("fixturename")-Decorator genutzt werden.
from typing import Generator
import pytest
from sqlalchemy.orm import Session
@pytest.fixture(autouse=False, scope="function")
def create_test_sql() -> Generator[Session, None, None]:
# create_test_sql_table
# create sql connection
yield sql_session
# delete sql connection
# delete sql tables
def test_sql_table(create_test_sql: Session) -> None:
# executes a test on the test db
assert create_test_sql.query(HelloWorldTable).get("hello") == "world"
Ein Test kann mehrere unabhängige Fixtures nutzen.
Fixtures, die für alle Tests verfügbar sein sollen, werden in der conftest.py im tests-Ordner abgelegt.
Eine in der conftest.py definierte Fixture muss in Tests nicht importiert werden.
Für schnelle und performante Datenbanktests wird empfohlen, diese als In-Memory-Datei anzulegen.
Dies geschieht bei SQLite mit dem Pfad sqlite:\\\:memory:.
Fixtures, die den yield-Operator verwenden, haben den Rückgabetyp Generator[SomethingYielded, None, None].
Fixtures ähneln Kontextmanagern.
Mock
In manchen Situationen müssen Softwareteile für effiziente Tests überschrieben werden. Beispiele hierfür sind Netzwerkverbindungen und redundante, zeitaufwendige Berechnungen.
Mocks werden in Fixtures oder innerhalb von Kontextmanagern verwendet. Dies kan auch in Fixtures kombiniert werden, um Wiederverwendbarkeit zu fördern. Natürlich ist es sinnvoll mehrere abhängige Mocks in einer Fixture zusammenzufassen.
Beispiel pytest-mock
In manchen Fällen ist es nicht ausreichend, nur das Ergebnis einer Anfrage zu überprüfen.
Stattdessen muss untersucht werden, welche internen Funktionen aufgerufen werden.
pytest-mock kann hierbei verwendet werden.
Mit pytest-mock lassen sich Funktionsaufrufe und deren Ergebnisse aufzeichnen und anschließend analysieren.
Dies ermöglicht beispielsweise Aussagen darüber, ob Caching-Operationen erfolgreich waren.
class Foo(object):
def bar(self, v):
return v * 2
def test_spy_method(mocker) -> None:
foo = Foo()
spy = mocker.spy(foo, 'bar')
assert foo.bar(21) == 42
spy.assert_called_once_with(21)
assert spy.spy_return == 42
Beispiel requests-mock
Bei der Verwendung einer Anfrage (request) innerhalb eines Tests hängt der Test von der korrekten Serverantwort ab.
Es ist meist sinnvoller, solche Anfragen zu überschreiben.
Dieser Ansatz ist zuverlässiger, deterministischer und schneller.
Interaktionen mit anderen Komponenten eines Softwarekomplexes werden in Integrationstests behandelt nicht in Unit-Tests.
import requests
import requests_mock
def test_mock_requests() -> None:
with requests_mock.Mocker() as m:
m.get('http://test.com', text='data')
assert requests.get('http://test.com').status_code == 200
Beispiel MonkeyPatch
Pytest's MonkeyPatch kann genutzt werden, um viele Werte temporär zu überschreiben, wie zum Beispiel Umgebungsvariablen und Funktionen.
Das folgende Beispiel zeigt, wie eine Umgebungsvariable für die Dauer eines Tests überschrieben wird.
import os
def test_partial(monkeypatch):
assert not os.getenv("SOME_ENV_VAR")
monkeypatch.setenv("SOME_ENV_VAR", "SOME_VALUE")
assert os.getenv("SOME_ENV_VAR") == "SOME_VALUE"
parametrize
Oft ist es sinnvoll, einen Test mit verschiedenen Werten durchzuführen.
Dafür ist eine For-Schleife ungeeignet, da ein Test bei der ersten fehlschlagenden Assertion abbricht.
Eine Möglichkeit, die Code-Duplikation vermeidet, ist die Auslagerung der Schleife mit dem pytest.mark.parametrize-Decorator.
import pytest
@pytest.mark.parametrize(
("a", "b"),
[(2, 4), (3, 9), (4, 6)],
)
def test_sqr(a: int, b: int) -> None:
assert a**2 == b
def test_sqr_wrong() -> None:
for a, b in [(2, 4), (3, 9), (4, 6)]:
assert a**2 == b
Der pytest-Decorator erwartet zuerst ein Tupel der Argumentnamen und als Zweites eine Liste der Wertetupel welche später Entpackt werden.
Bei nur einem Parameter kann dieser direkt als String benannt werden.
Mehrere parametrize-Decorator können verwendet werden, um ein mehrdimensionales, unabhängiges Parameterfeld aufzuspannen.
parametrize kann zusammen mit Fixtures verwendet werden.
pytest.raises
Manchmal ist es notwendig zu prüfen, ob ein Fehler korrekt ausgelöst wird, anstatt auf einen Rückgabewert zu achten.
pytest bietet dafür den pytest.raises Kontext an.
Dieser prüft, ob ein bestimmter Fehler ausgelöst wird und ermöglicht das druchführen weiterer Validierungen in diesem Kontext.
import pytest
def i_raise_an_error() -> None:
raise ValueError("Happy to provide an example!")
def test_value_error_raise():
with pytest.raises(ValueError, match="Happy"):
i_raise_an_error()
Der Beispielcode überprüft, ob eine Funktion einen ValueError auslöst. Zusätzlich wird geprüft, ob der Fehler die Zeichenkette "Happy" enthält. Schlägt der Test fehl, liegt es daran, dass der Fehler nicht wie erwartet ausgelöst wird oder das Wort "Happy" nicht enthält.
Code-Coverage
Beim Testen ist es wichtig, einen Überblick darüber zu haben, welche Codebereiche bereits getestet sind und welche noch nicht. Eine Möglichkeit, dies zu tun, ist die Verwendung von Code-Coverage. Dieses Tool zählt, wie oft jede Codezeile beim Testen ausgeführt wird und überprüft, welcher Verzweigung im Code gefolgt wird. Das Coverage lässt sich als Metrik (meist in Prozent) darüber welcher anteil des Codes beim Testen ausgeführt wurde darstellen oder visuell aufbereiten, um aufzuzeigen, wo noch Tests fehlen. In einigen IDEs wird dies durch farbliche Hervorhebungen umgesetzt. Es ist nicht unüblich, die Code-Coverage über Tools wie SonarQube anzuzeigen und Änderungen zu verfolgen.
Es ist wichtig, die Grenzen dieser Metriken und Markierungen zu kennen:
- Code-Coverage zählt die Ausführungen pro Codezeile, nicht die sinnvolle Prüfung von Rückgabewerten oder Funktionsergebnissen.
- Code-Coverage existiert auch, wenn nur die äußerste Methode getestet wird, aber es ist ökonomischer, erst innere Funktionen einzeln zu testen.
- Je kleiner der zu testende Codeabschnitt, desto schneller der Test.
- Jede Abzweigung benötigt mindestens einen weiteren Test. Verschachtelte Abzweigungen sind multiplikativ. Im Englischen spricht man dabei vom Condition Coverage oder Branch Coverage.
- Eine Code-Zeile ist ein Befehl. Ein Befehl über mehrere Zeilen gilt als eine Zeile für die Coverage-Analyse.
Verzerrte Metriken erschweren ein aussagekräftiges Bild über die Testqualität.
Im Test-Driven Development werden Tests vor oder während der Funktionsentwicklung geschrieben. Obwohl dies die Lehrbuchvariante ist, wird es selten so praktiziert. Wichtig ist jedoch, dass Tests so schnell wie möglich erstellt werden. Das Erstellen von Tests zur Sicherstellung der Funktionalität bei Änderungen wird empfohlen. Je früher ein Test erstellt wird, desto früher bring dieser nutzen. Wird ein Test erst nachträglich erstellt, ist der Nutzen am geringsten.
Wird eine Funktion oder Klasse in einem Jupyter-Notebook entwickelt empfiehlt sich das ipytest package.
Dieses erlaubt die Nutzung von pytest innerhalb von Jupyter-Notebooks.
Die meisten Softwareprojekte haben eine untere Grenze für das Code-Coverage für neuen oder modifizierten Code.
Ein allgemeiner Standardwert liegt bei 80 %.
Das bedeutet, dass Code nur dann dem main-Branch hinzugefügt werden darf, wenn mindestens 80 % des Codes beim Testen ausgeführt werden.
Normalerweise wird die Code-Coverage in einem Werkzeug wie SonarQube mitgeschrieben und visualisiert. GitHub bietet dazu keine native Möglichkeit an. Es gibt über den Marketspace dazu Werkzeuge, welche aber meist auf Organisationsebene eingebunden werden müssen. Und das Aufsetzen von SonarQube für die Dauer des Projektes wurde hier als nicht sinnvoll angesehen.
Sphinx
Sphinx ist ein weit verbreitetes Werkzeug zur Erstellung von Python-Dokumentationen.
Viele Werkzeuge verwenden sphinx mit einem ReadTheDocs-Layout für ihre Projektdokumentationen.
sphinx unterstützt zahlreiche andere Layouts.
Dies ist auch für unsere Projektdokumentation sinnvoll.
Sphinx-Konfigurationen sind nicht Teil der pyproject.toml.
Zum Erstellen von Sphinx-Projekten existiert ein CLI-Interface.
Dieses kann mit dem Befehl sphinx-quickstart aufgerufen werden.
Es wird ein Verzeichnis für die Dokumentation erstellt, bei uns ist dies das documentations-Verzeichnis.
Dort befinden sich eine makefile für Linux und eine make.bat für Windows.
Beide erzeugen verschiedene Ausgabeformate.
Relevant für uns sind die Formate html und latexpdf.
Neben diesen liegt die index.rst, die als Startseite der Dokumentation dient und eine conf.py.
index.rst
In der index.rst können Inhaltsverzeichnisse und API-Dokumentationen referenziert werden.
Inhaltsverzeichnisse listen Dokumente auf, optional unter Verwendung von glob.
Das erste Inhaltsverzeichnis wird durchnummeriert, das zweite nicht.
Fancy Dockumentation
====================
Welcome.
Below you will find two Table of Content on of the generell documentation.
a second Table of Contents (TOC) containing the API docs for `my_fancy_package`
.. toctree::
:glob:
:maxdepth: 3
:caption: Main Content
:numbered:
some-other-file
a-folder-full-of-files/*
.. toctree::
:maxdepth: 6
:caption: Modules
modules
.. automodule:: my_fancy_package
:members:
:undoc-members:
:show-inheritance:
:inherited-members:
:autodoc_member_order:
Plugins
Sphinx ist eine Pluginhölle.
Sogar plugins können plugins haben. So zum Beispiel der myst_parser.
Hier ist eine Liste der verwendeten Plugins.
- sphinx.ext.autodoc: Dieses Plugin automatisiert die Dokumentation von Python-Quellcode. Es extrahiert Dokumentation aus den Docstrings der Module, Klassen, Funktionen und Methoden.
- nbsphinx: Ermöglicht die Integration von Jupyter Notebooks in Sphinx-Dokumentation. Es konvertiert Notebooks in Sphinx-Dokumente, wobei die Inhalte der Notebooks direkt gerendert werden.
- myst_parser: Ein Parser, der Markdown-Dateien in Sphinx verarbeitet. Er unterstützt erweiterte Markdown-Features und ermöglicht die Verwendung von Sphinx-spezifischen Direktiven in Markdown.
- sphinx.ext.napoleon: Dieses Plugin ermöglicht es Sphinx, Docstrings zu parsen, die im NumPy- oder Google-Stil verfasst sind. Es macht die Integration solcher Docstrings in die generierte Dokumentation einfacher und übersichtlicher.
- sphinx_copybutton: Fügt einen "Kopieren"-Button zu Codeblöcken in der Sphinx-Dokumentation hinzu. Dies erleichtert es dem Benutzer, Code-Snippets zu kopieren.
- sphinx_autodoc_typehints: Dieses Plugin fügt automatisch Typenhinweise aus Python-Funktionen und -Methoden in die Sphinx-Dokumentation ein. Es hilft, die Dokumentation klarer und informativer zu gestalten.
- sphinx.ext.intersphinx: Ermöglicht das Verlinken zu Dokumentationen anderer Projekte, die mit Sphinx erstellt wurden. Dieses Plugin unterstützt das Erstellen von Querverweisen zwischen verschiedenen Sphinx-Dokumentationen.
- sphinx.ext.autosectionlabel: Generiert automatisch Labels für jede Sektionstitel in der Dokumentation. Dies vereinfacht das Verlinken innerhalb der Dokumentation.
- sphinx.ext.viewcode: Fügt Links zu den Quellcode-Dateien neben den dokumentierten Python-Objekten hinzu. Dies ermöglicht es dem Benutzer, direkt vom Dokument zum entsprechenden Quellcode zu springen.
- IPython.sphinxext.ipython_console_highlighting: Bietet Syntax-Highlighting für IPython-Interaktionskonsolen in Sphinx-Dokumentationen. Dies verbessert die Lesbarkeit von IPython-Codebeispielen.
- sphinxcontrib.mermaid: Erlaubt die Integration von Mermaid-Diagrammen in Sphinx-Dokumentationen. Mermaid ist ein Tool zur Erstellung von Diagrammen und Flussdiagrammen mittels Textbeschreibungen.
- notfound.extension: Zeigt eine benutzerdefinierte 404-Seite in der HTML-Dokumentation, wenn eine Seite nicht gefunden wird. Dies verbessert die Benutzererfahrung bei fehlenden Seiten.
- sphinxcontrib.drawio: Integriert draw.io-Diagramme in Sphinx-Dokumentation. Dies ermöglicht es, komplexe Diagramme direkt in die Dokumentation einzubinden.
- sphinx_git: Ein Plugin für Sphinx, das es ermöglicht, Informationen aus einem Git-Repository in Dokumentationen einzufügen. Dies kann zum Anzeigen von Versionsinformationen oder zur Verfolgung von Änderungen verwendet werden.
Besonders hervorzuheben finde ich die Interaktionen der verschiedenen Plugins.
sphinx_autodoc_typehints integriert wunderbar die Links welche von sphinx.ext.intersphinx bereitgestellt werden.
Dies macht einen Einstieg in Sphinx lieder sehr mühsam.
conf.py
Die conf.py ist eine Datei im documentation-Verzeichnis.
Sie konfiguriert Elemente wie Titel, Versionsnummern und Plugins.
Einstellungen wie Typisierungsstil und Verlinkungen zu Fremddokumentationen sind hier definierbar.
So können beispielsweise Rückgabewerte vom Typ pd.DataFrame mit der pandas-Dokumentation verlinkt werden.
Einmal erstellte Konfigurationen können oft größtenteils von Projekt zu Projekt übernommen werden.
Auch die Pfade für custom.css und das Standard-HTML-Theme werden hier festgelegt.
API-DOCS
Sphinx kann aus Docstrings eine API-Dokumentation erstellen.
Vor dem Bauen mit make muss dazu der Befehl sphinx-apidoc im documentation-Verzeichnis ausgeführt werden.
Docstrings - Google-Style
In diesem Projekt wurde sich zu Anfang geeinigt, das Google-Style docstrings verwendet werden sollen. Die volle Dokumentation dazu findet sich hier.
GitHub
Die FH-SWF hat uns ein GitHub-Repository bereitgestellt. Dies dient als zentraler Ort zur Versionierung des Projekts und zum Abgleich der Entwicklungsstände des Teams. Eine detaillierte Erklärung von Git würde hier zu weit führen.
Pull Requests
Git-Repositories ermöglichen die Entwicklung einzelner Entwicklungsstränge (Branches) lokal, die dann zentral synchronisiert werden. Ein abgeschlossener Entwicklungsstrang wird auf den Default-Branch zurückgeführt. Die richtige Größe solcher Entwicklungen zu finden, ist herausfordernd, da große und langwierige Entwicklungen schwer zu integrieren sind.
Bei Git-Projekten wird in der Regel ein formeller Antrag, ein sogenannter Pull Request (PR), gestellt.
In anderen Systemen wird dies als Merge Request bezeichnet.
Es wurde festgelegt, dass Änderungen, die dem main-Branch hinzugefügt werden sollen, von mindestens einer Person korrektur gelesen werden müssen.
Die Genehmigung eines Pull Requests hängt von der positiven Bewertung ab.
Änderungsvorschläge sind normal und wünschenswert, um die Qualität des Projekts zu steigern.
Es ist üblich, ein Teammitglied, das mit dem speziellen Thema vertraut ist, um ein Code Review zu bitten.
Dies erfolgt über den entsprechenden Button im Verlauf des Pull Requests.
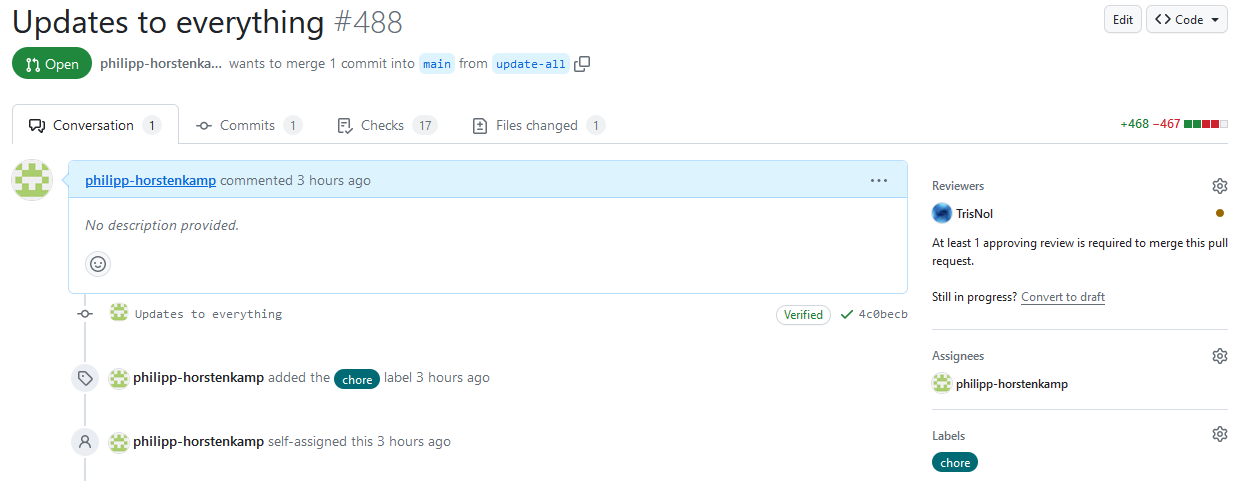
Es wurde auch festgelegt, dass nur Pull Requests gemerged werden können, für die alle Tests erfolgreich waren.
Dies lässt sich durch Branch-Protection-Regeln in den Repository-Einstellungen unter dem Tab Branches festlegen.

Actions
GitHub Actions ist die Lösung von GitHub für das Erstellen und Durchführen von CI/CD-Pipelines.
Arbeitsflüsse (workflows) werden definiert und bei Bedarf ausgeführt.
workflows werden im .github\workflows-Verzeichnis als *.yaml-Dateien definiert.
Hier ein Beispiel für einen einfachen workflow:
name: Python-Lint # the name of the workflow
on: # defines when an actin should be triggered (more detailed specifications are possible)
push:
pull_request:
jobs: # lists the jobs that should be run in the workflow
ruff: # the id of a job
runs-on: ubuntu-latest # defines on what kind of maschine the job should be executed. latest can only be used if the specific version does not matter
# needs: something # defines if another job needs to be executed before (is needed)
steps: # defines the steps of the workflow
- uses: actions/checkout@v4 # uses an action (dokumentation on: github.com/actions/checkout)
- uses: chartboost/ruff-action@v1 # uses an action (dokumentation on: github.com/chartboost/ruff-action)
with: # Defines arguments for an action
version: 0.1.9 # An argument as requested by an action
- name: Finishline # name of the step
run: | # Runs a script with multiple lines
echo All done!
echo Really everything is done!
Ein komplexerer Workflow kümmert sich um das Ausführen von pytest und das Mitschreiben des Code-Coverages:
name: Test & Build
on:
push:
pull_request:
types: [reopened, opened]
jobs:
test:
name: Pytest
runs-on: ubuntu-latest
timeout-minutes: 10
steps:
- uses: actions/checkout@v4
- name: Install poetry
run: pipx install poetry
- name: Set up python
id: setup-python
uses: actions/setup-python@v5
with:
python-version: '3.11'
cache: poetry
- run: poetry install --without develop,doc,lint --all-extras
- name: Run test suite
run: |
poetry run pytest --junit-xml=unit-test-results.xml \
--cov-report "xml:coverage.xml" --cov=src --disable-warnings tests/
- name: Archive code coverage results
uses: actions/upload-artifact@v4
with:
name: code-coverage-report
path: |
coverage.xml
.coverage
if-no-files-found: error
- name: Archive unit test results
uses: actions/upload-artifact@v4
with:
name: test-report
path: |
unit-test-results.xml
if-no-files-found: error
Der obenstehende Ausschnitt aus dem Workflow, der sich auf das Bauen und Testen des Projekts konzentriert, illustriert ausschließlich das Testen mit pytest.
Dieser Abschnitt veranschaulicht einige Feinheiten bei der Erstellung von workflows für Python.
Eine Schritt-für-Schritt-Beschreibung verdeutlicht den Prozess:
- Der
workflowwird bei jedem Push nach GitHub sowie bei der Erstellung und Wiedereröffnung geschlossener PRs ausgeführt. - Der hier gezeigte einzige
jobträgt den Namen Pytest. - Er wird auf der neuesten Ubuntu-Version ausgeführt.
- Nach 10 Minuten erreicht der Pytest
jobein Timeout. - Der gepushte oder PR-Branch wird ausgecheckt, was überschrieben werden kann.
- Anschließend wird
poetrymittelspipxinstalliert.pipxist eine Variante vonpip, die Python-Software nicht als Python-Abhängigkeit, sondern als ausführbares Python-Skript installiert. - Python wird eingerichtet.
Die
PATH-Variable wird auf die erforderliche Python-Installation gesetzt. Falls die notwendige Python-Version nicht vorinstalliert ist, wird sie von der Aktion nachinstalliert. Es ist zu beachten, dass keine Linux-ARM-Distributionen unterstützt werden. Nur wenn die Python-Installation konfiguriert wird, können die zugehörigen Caches genutzt werden. Hier kommt der Poetry-Cache zum Einsatz. Für jedespoetry-Projekt im Repository wird ein separater Cache angelegt, was den Prozess erheblich beschleunigt. Caches sind auch für andere Abhängigkeitsverwaltungen als Poetry verfügbar, jedoch nur, wenn die Python-Version explizit definiert wird. poetryinstalliert selektiv die erforderlichen Abhängigkeitsgruppen für das Testen.pytestführt die Tests durch und erstellt Protokolle in verschiedenen Formaten, darunter ein Unittest-Protokoll und ein Code-Coverage-Protokoll.- Die Berichte werden für nachfolgende Aktionen bereitgestellt und können von den Nutzern heruntergeladen werden.
Die Workflows werden für Pushes und PRs aus dem entsprechenden Branch heraus ausgeführt.
Bei Pushen und PRs werden die Workflows aus dem entsprechenden Branch verwendet.
GitHub Actions führen alle jobs parallel aus, im Gegensatz zu sequentiellen Abläufen bei anderen CI/CD-Tools wie z.B. Jenkins.
GitHub Actions ermöglichen parametrisierte Matrix Builds.
Sie müssen in den Repository-Einstellungen unter Actions aktiviert werden.
Eine vollständige Schemabeschreibung für GitHub workflows findet sich hier.
Implementierte Workflows
Für dieses Projekt wurden folgende Workflows implementiert:
-
Python-Lint:
- Führt verschiedene Linter aus, um die aktuelle Version des Projekts auf Konformität zu prüfen.
- Das Linting wird bei jedem Push und bei jedem Öffnen eines Pull Requests ausgeführt.
- Der Bericht listet Fehler auf.

- Zu den Lintern gehören
black,ruffundmypy. - Die Abhängigkeitsvalidierung umfasst:
- Export der
requirements.txt. pip-auditfür Laufzeit-Abhängigkeiten.pip-licenses, nur als Bericht für Laufzeit-Abhängigkeiten.
- Export der
-
Test & Build:
- Testet und baut die Software.
- Alle Berichte werden als Artefakte bereitgestellt.
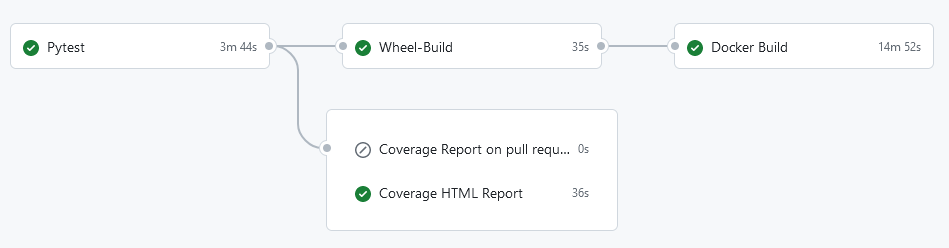
- Pull Requests werden mit Angaben zum Code-Coverage kommentiert.

pytestwird für Tests ausgeführt.- Das Code-Coverage wird analysiert, um das Mergen bei unzureichender Abdeckung zu verweigern (nur bei Pull Requests).
- Das Code-Coverage wird visualisiert, um eine Übersicht über die Testabdeckung auch ohne passende IDE zu bieten.
- Parallel zur Analyse werden eine Python-Wheel (
*.whl) und ein Python-Projekt (*.tar.gz) erstellt. - Mit dem Python Wheel wird das Docker-Image gebaut.
- Das Image wird unter dem Tag
mainbereitgestellt, wenn es vommain-Branch gebaut wird. - Für verschiedene Docker-Container gibt es spezifische Abhängigkeitsdefinitionen in unserem Poetry-Python-Projekt, die pro
targetin der Dockerfile nachinstalliert werden.
-
Documentation-Action:
- Baut die Dokumentation mit
sphinxund lädt sie als GitHub Pages hoch. - Der Dokumentationsbau erstellt eine HTML-Webseite mit Sphinx.
- Die Dokumentation wird nur in Pull Requests oder auf dem
main-Branch bereitgestellt und kann heruntergeladen werden. - Die Bereitstellung der Dokumentation erfolgt nur auf dem
main-Branch und wird als externe Webseite auf den GitHub Pages veröffentlicht.
- Baut die Dokumentation mit
Self-Hosted Act-Runner
Zu Beginn des Projekts erhielten wir die Information, dass die FH-SWF keine Cloud-Ressourcen zur Verfügung stellen kann. Deshalb wurde anfänglich versucht, einen Runner lokal auf einem Raspberry Pi 4 zu installieren. Die Einrichtung gemäß der GitHub-Anleitung war relativ einfach, stieß jedoch aufgrund der nicht unterstützten ARM32/ARM64-Architektur bei der Nutzung von Python auf Probleme.
- Die
actions/setup-python-Aktion unterstützt ARM für Linux nicht. Ein Fallback auf eine installierte Python-Version ist jedoch möglich. - Viele Python-Wheels sind nicht für ARM gebaut und müssen lokal kompiliert werden, besonders wenn sie Cython- oder Rust-Komponenten enthalten.
- Ohne Angabe der Python-Version unterstützt die
actions/setup-python-Aktion keinen Python-Poetry-Cache. - Einige KI-Modelle lassen sich auf dem Raspberry Pi nicht ausführen, da er nicht genügend RAM hat.
- Geringe Parallelisierung und langsame Prozessoren führen zu langen Wartezeiten bei Tests und Linting-Ergebnissen.
- Das Risiko, von GitHub aufgrund zu vieler Downloads gesperrt zu werden, ist geringer.
- GitHub Actions sind für Open-Source-Projekte kostenlos, weshalb es relativ wenig Dokumentation zum Hosting eigener Runner gibt.
Letztendlich wurde uns jedoch die Nutzung von GitHub Actions über den FH-SWF-Account ermöglicht, sodass der self-hosted Runner nicht zum Einsatz kommen musste. Zur Zeit Nutze ich persönlich den Gitea's Act Runner welcher ein Fork von GitHubs self-hosted Runner ist. Es ist also möglich diesen zu Nutzen. Dies hat aber eindeutige Grenzen und ist bei weitem nicht so komfortabel, ist aber mit nicht ARM32/64 Geräten gut möglich.
Die Anleitung von GitHub zu self-hosted Runners ist hier zu finden.
Erwartete Artefakte
Die derzeit konzipierten Pipelines erstellen folgende Artefakte:
- Ein Python Wheel.
- Test Coverage.
- Einen Bericht über die verwendeten Laufzeitabhängigkeiten.
- Eine
requirements.txt. - Einen Bericht über die genutzten Lizenzen, erstellt von
pip-license. - Einen Bericht über potenzielle Sicherheitslücken in den Abhängigkeiten, erstellt von
pip-audit.
- Eine
Dependabot
Dependabot, der GitHub OWASP-Scanner, ermöglicht es, den Standard-Branch eines Projekts regelmäßig auf Sicherheitslücken in Abhängigkeiten zu überprüfen.
Abhängig von der Konfiguration kann Dependabot Handlungsempfehlungen aussprechen oder automatisch Pull Requests erstellen, um Sicherheitslücken zu schließen.
Für unser Projekt ist der Einsatz von Dependabot aktuell nicht geplant.
Dies liegt daran, dass es mit pip-audit redundant wäre und erst nach Abschluss der aktiven Entwicklungsphase des Projekts Vorteile bietet.
Dependabot kann Routineaufgaben übernehmen, insbesondere, wenn GitHub Actions implementiert sind und vorgeschlagene Änderungen sofort testen.
Dependabot unterstützt eine Vielzahl von Programmiersprachen und Tools zur Abhängigkeitsverwaltung.
Es ermöglicht nicht nur Scans von Python-Abhängigkeiten, sondern auch das Scannen und Aktualisieren von GitHub Actions.
Natürlich wäre es einfach möglich nur Dependabot zu nutzen. Da ich aber im beruflichen Kontext pip-audit verwende, war dies einfacher.
pre-commit
Oft in der Softwareentwicklung gezeigt wird das Kostendiagramm für Fehler, das die zunehmenden Kosten von Fehlern über die Zeit illustriert.
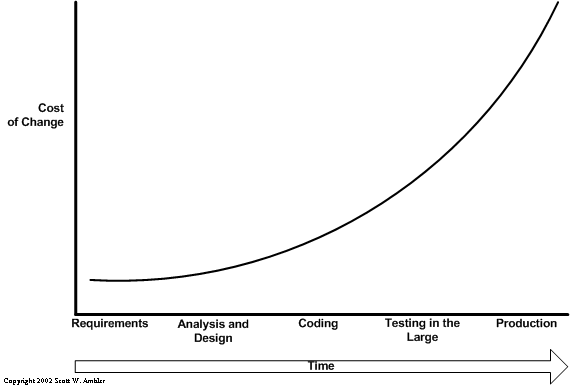
Es verdeutlicht, dass die Kosten für das Beheben eines Fehlers mit der Zeit ansteigen.
pre-commit, ein Python-Tool, adressiert dieses Problem.
Es hängt sich in die git-hooks-Mechanik ein und validiert geänderte Dateien vor dem Committen.
Durch den selektiven Einsatz von Lintern und Formatierern wird sichergestellt, dass nur qualitativ hochwertiger Code committet wird.
Nur die Hooks, die auf die aktuell geänderten Dateiformate zutreffen, werden ausgeführt.
Hilfestellungen und automatische Fixes bieten bei Bedarf schnelle Lösungen und schlagen eine überarbeitete Version vor.
Diese überarbeitete Version kann dann mit der gestagten Version abgeglichen und übernommen werden.
Meist garantieren die Hooks eine unveränderte Funktionalität.
Ich persönlich hatte an dieser Stelle bisher noch nie Probleme.
Programmierer müssen sich mit Themen wie Importreihenfolge und Whitespace-Formatierung auseinandersetzen. Dadurch ist auch bei diesen Details die Qualität gewährleistet öhne die Kosten zu erhöhen. Typisierungsfehler können dem Programmierer schon während des Committens aufgezeigt werden. Dies trägt dazu bei, dass potenzielle Fehler schon vor dem Testing, aber direkt beim oder nach dem Codieren auffallen. Das beschleunigt den Programmierprozess und senkt damit wieder die Kosten. Auch wenn wir in einem akademischen Projekt keine Kosten in EUR haben ist die benötigte Zeit natürlich immer noch ein Faktor.
Um pre-commit zu nutzen, müssen neben Git und Python auch das pre-commit-Paket installiert werden.
Nach der Installation wird das pre-commit-Skript im .git/hooks/-Verzeichnis eingehängt, was durch den Befehl pre-commit install geschieht.
Das pre-commit-Skript im .git/hooks/-Verzeichnis wird dann vor jedem Commit ausgeführt.
Scheitert einer der Tests oder werden Änderungen vorgeschlagen, wird der Commit abgebrochen.
pre-commit wird durch eine .pre-commit-config.yaml im Root-Verzeichnis eines Projekts konfiguriert.
Es gibt im git-workflow viele verschiedene Stellen um hooks einzuhängen.
In dieser Dokumentation wird nur auf die Validierung/Formattierung vor dem Committen eingegangen.
Hier ein Beispiel einer .pre-commit-config.yaml:
default_language_version:
python: python3.11
default_stages:
- pre-commit
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.5.0
hooks:
- id: end-of-file-fixer
exclude: (.txt$|.ipynb$)
In diesem Beispiel wird Python 3.11 als Standardversion festgelegt und die Hooks werden standardmäßig nur im pre-commit-Stadium verwendet.
Es wird ein Git-Repository als Quelle für eine Reihe von Hooks definiert.
Der Hook end-of-file-fixer wird ausgeführt und dabei werden *.txt und *.ipynb-Dateien ausgeschlossen.
Mehrere Repos und Hooks pro Repo können definiert werden.
Der Befehl pre-commit autoupdate aktualisiert die Versionsdefinitionen.
Neue Repos oder andere Versionen werden bei der ersten Ausführung einmalig installiert.
Hier eine übersicht der für dieses Projekt verwenden hooks:
- end-of-file-fixer: Stellt sicher, dass Dateien mit einer leeren Zeile am Ende enden.
- trailing-whitespace: Entfernt überflüssige Leerzeichen am Ende von Zeilen.
- check-yaml: Überprüft die syntaktische Korrektheit von YAML-Dateien.
- check-json: Überprüft die syntaktische Korrektheit von JSON-Dateien.
- check-toml: Überprüft die syntaktische Korrektheit von TOML-Dateien.
- check-xml: Überprüft die syntaktische Korrektheit von XML-Dateien.
- check-ast: Überprüft Python-Dateien auf Syntaxfehler.
- check-added-large-files: Verhindert das versehentliche Hinzufügen großer Dateien zum Repository.
- name-tests-test: Stellt sicher, dass Testdateien mit
testbeginnen. - detect-private-key: Erkennt und verhindert das Hinzufügen von privaten Schlüsseln zum Repository.
- check-case-conflict: Verhindert Probleme mit Dateinamen, die sich nur in der Groß-/Kleinschreibung unterscheiden.
- check-symlinks: Überprüft symbolische Verknüpfungen auf Gültigkeit.
- check-docstring-first: Stellt sicher, dass Dateien mit einem Docstring beginnen.
- mixed-line-ending: Vereinheitlicht die Zeilenendungen in Dateien.
- destroyed-symlinks: Erkennt zerstörte symbolische Verknüpfungen.
- debug-statements: Erkennt und meldet Debug-Anweisungen in Python-Code.
- pretty-format-json: Formatiert JSON-Dateien in einem einheitlichen Stil.
- no-commit-to-branch: Verhindert das direkte Commiten in geschützte Branches. Bei uns
main. - ruff: Ein schneller Python-Linter und Code-Formatter (hier vorgestellt).
- black: Ein Python-Code-Formatter (hier vorgestellt).
- black-jupyter: Formatiert Jupyter Notebooks mit Black (hier vorgestellt).
- pretty-format-ini: Formatiert INI-Dateien in einem einheitlichen Stil.
- pretty-format-yaml: Formatiert YAML-Dateien in einem einheitlichen Stil.
- pretty-format-toml: Formatiert TOML-Dateien in einem einheitlichen Stil.
- mypy: Ein statischer Typenprüfer für Python (hier vorgestellt).
- md-toc: Erzeugt automatisch ein Inhaltsverzeichnis für Markdown-Dateien.
- poetry-check: Überprüft die Konsistenz einer Poetry-Projektdatei.
- poetry-install: Installiert Abhängigkeiten mit Poetry.
- validate-html: Überprüft die Korrektheit von HTML-Dateien.
- check-github-workflows: Überprüft GitHub Workflow-Dateien auf Korrektheit.
- auto-walrus: Automatisiert die Verwendung des Walrus-Operators in Python. Um ein Bewusstsein zu schaffen, wann dieser Verwendet werden kann.
Auf prettier wurde verzichtet, da es sich um ein Node.js-Paket handelt, das die Installation von Node.js bei allen Teammitgliedern erfordert.
prettier könnte für das Projekt benötigte *.css-Dateien formatieren.
Einige der Hooks kamen nicht oder nur selten zum Einsatz.
Sie waren Teil der verwendeten Repositories und wurden nur ausgeführt, wenn sie für eine spezifische Datei benötigt wurden.
Somit gab es keinen Nachteil darin, selten verwendete Hooks zu unterstützen.
Langsame Hooks wie mypy sind hinsichtlich der Ausführungszeit kritischer.
Allerdings bietet mypy aufgrund seiner statischen Typ-Prüfung einen besonders hohen Mehrwert.
Bei der Nutzung von pre-commit neben poetry empfehle ich das poetry-pre-commit-plugin.
Dieses Plugin führt pre-commit install aus, wenn pre-commit über poetry installiert wird.
So wird verhindert, dass dieser einfache und schnelle Schritt nach dem git clone vergessen wird.
pre-commit-Konfigurationen lassen sich fast vollständig von einem Projekt auf ein anderes übertragen.
Die einzige Ausnahme bildet die mypy-Definition, da hier auch *-stubs/*-typing-Abhängigkeiten hinterlegt werden müssen.
pre-commit installiert jedes Hook-Repository in einer eigenen virtuellen Umgebung.
Das Commit-Log unter Verwendung von pre-commit kann folgendermaßen aussehen:

Die vollständige Dokumentation von pre-commit finden Sie hier.
Den offiziellen Katalog über die verwendbaren Hooks finden Sie hier.
Pre-commit Hooks haben oft eine große Überschneidung mit der zentralen Pipeline auf einem Build-Server.
Dies ist beabsichtigt.
Ein Pre-commit Hook ermöglicht schnelle Rückmeldungen, die nicht direkt in der IDE angezeigt werden.
CI/CD-Pipelines benötigen in der Regel mehr Zeit, da sie das gesamte Projekt bearbeiten.
Sie lassen sich nicht so einfach umgehen, da Pre-Commit Pipelines eher suggestiv wirken.
Der Overhead für autofixes, die von einer pre-commit Hook-Kollektion stammen, ist in einer zentralen CI/CD-Pipeline unerwünscht.
Die durch pre-commit Hooks durchgesetzten Regeln sind oft weichere Konventionen, die automatische Fixes bereitstellen.
Diese können durch einfaches und oft nur einmaliges Deaktivieren bewusst umgangen werden.
Andererseits vermeidet man aufwendige Verifikationen, wie Unit-Testing, in Pre-Commit Hooks, da diese zu langsam sind und Entwickler unnötig aufhalten könnten.
Diese Unterschiede lassen sich auch zusammen fassen als: pre-commit Hooks erleichtern Entwicklern das Einhalten bestimmter Standards, während CI/CD-Pipelines die Einhaltung von Projektstandards garantieren.
pre-commit ci
pre-commit.ci ist eine CI/CD-Lösung, die in GitHub integriert werden kann und dort pre-commit als Linter ausführt.
Da die Ergebnisse in hohem Maße gecacht werden, ist dies extrem schnell.
Diese Lösung ist jedoch bei nicht öffentlichen Projekten kostenpflichtig und kam daher in diesem Projekt nicht zum Einsatz.
Ich weiß es zu schätzen, dass einige der in pre-commit verwendeten Linter in pre-commit.ci explizit umgangen werden können, ohne eine formelle Ausnahme zu definieren.
Leider ist pre-commit.ci derzeit nur für GitHub verfügbar.
Zustimmung vom Team
Da das DevOps- und CI/CD-Setup zumindest initial für ein Projekt vorhanden sein muss, um Mehrwert zu erzeugen und nicht nur Mehrarbeit, wurden alle Werkzeuge in einem Development-Branch zusammengestellt und konfiguriert.
Obwohl CI/CD stark formalisiertes maschinelles Testen beinhaltet, funktioniert es nicht ohne das Buy-In des Entwicklungsteams. Daher wurde bei der Präsentation dieser Werkzeuge die Zustimmung des Teams für dieses Vorgehen eingeholt.
Die Zustimmung wurde erteilt, und ein erster Entwurf der Pipelines und Tools wurde in Betrieb genommen.
Fazit
Es gibt zahlreiche hilfreiche Werkzeuge für die Softwareentwicklung.
Allein im Bereich CI/CD für Python den Überblick zu behalten und zu entscheiden, was nützlich ist oder sein könnte, ist eine Frage der Erfahrung.
Die Einschätzung der damit verbundenen Kosten gehört ebenfalls dazu.
Es erscheinen ständig neue Werkzeuge.
In anderen Projekten habe ich beispielsweise bisher mit flake8 gearbeitet.
ruff, das weniger als ein Jahr alt und noch in den Versionen 0.0.* ist, übertrifft ältere Linter deutlich.
Ich bin zuversichtlich, dass die aktuelle Konfiguration der Werkzeuge prinzipiell funktionieren wird.
Sie muss jedoch kontinuierlich mit neueren Werkzeugen abgeglichen und deren praktischer Nutzen evaluiert werden.
Die Evaluation wird sehr von der Wahrnehmung dieser Werkzeuge abhängen.
Entscheidend ist, ob sie als Hilfestellungen oder als Einschränkungen empfunden werden.
Ich habe versucht möglichst selbstreparierende Werkzeuge auszuwählen, sodass ich dabei aber zuversichtlich bin.